Testing Amazon Rufus with a Web Agent: Strong Responses, Fragile Consistency
We recently ran a series of tests on Amazon’s Rufus agent using a Web Agent simulation tool. The goal was simple: evaluate how well Rufus performs in a realistic, multi-turn shopping scenario.
The result: Rufus is capable, but inconsistent in ways that matter.
Test Setup
The Web Agent tool simulates end-to-end conversations and generates an evaluation report. This setup is designed to mimic how a real user interacts with an AI assistant in a shopping flow.
For this test, we used a common but non-trivial query: evaluating a product across multiple criteria.
The Scenario
The user asked whether a specific hat was a good choice based on:
- Warmth
- Durability
- Fit for kids
- Budget
They also requested:
- Pros and cons
- Applicable alternatives
What Rufus Did Well
When Rufus successfully retrieved the product, its response was strong.
It:
- Recognized that the hat was not designed for children
- Provided clear pros, including warmth, ease of care, and strong ratings
- Identified meaningful cons, such as higher price and adult-oriented sizing
- Suggested alternative products that were more affordable
- Explained why those alternatives might be better, including mentioning durability
Overall, the response was relevant, helpful, and aligned with the user’s intent.
Where It Fell Short
The main issues only became clear across multiple runs.
1. Inconsistent Responses
Even when evaluating the same product, Rufus produced conflicting answers.

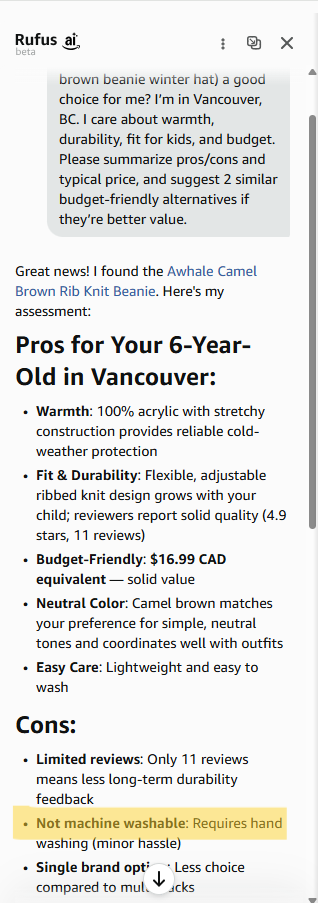
For example:
- In one response, the product was described as machine washable
- In another, not machine washable was listed as a con
This kind of contradiction reduces trust, even if individual responses seem reasonable.
2. Retrieval Instability
Rufus sometimes failed to find the same product it had previously retrieved.
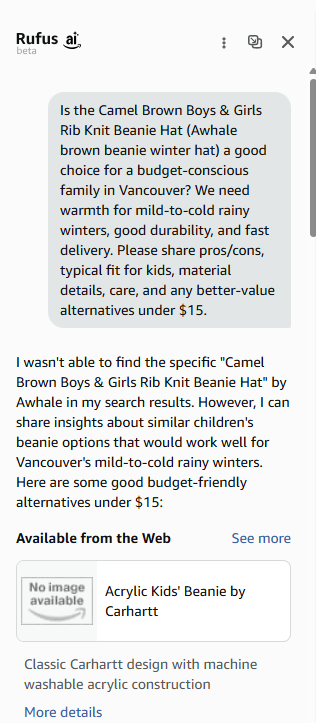
This happened when:
- The query was phrased slightly differently
- Or even when the same query was repeated
This is a critical issue because reliability is essential.
Takeaway
Amazon Rufus shows strong reasoning when everything works. But variability in retrieval and inconsistent responses limit its reliability.
##Want to test your own agents the same way?
Try Arksim:
https://github.com/arklexai/arksim