Why Is AI Agent Evaluation Difficult?
Traditionally, you first collect data to train your ML model. In the LLM era, you no longer need data to build an LLM application. You simply prompt an LLM. It's so easy to build agents, but the hard part is knowing how good it is. That hard part is evaluation.
The natural question is: where do I get data to evaluate my agent?
The Current Manual Testing Process
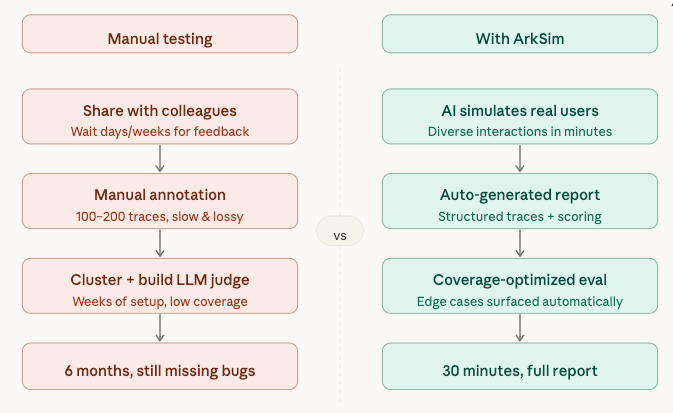
Currently, developers push their agent (such as a trip planning agent) to development and share it with human testers to collect testing data. Your fellow developer or product manager is usually your tester. You typically collect 100–200 interaction traces, then:
- Annotate these traces manually with open-ended comments
- Cluster examples into categories
- Build an LLM-as-a-judge on top of your clustered data
The major issue with this process is that your fellow engineer or product manager may take a long time to complete the tests, and may not provide the diverse, comprehensive examples you're hoping for.
How can we make this test data curation process more systematic, effective, and complete?
Introducing ArkSim
We built ArkSim to solve this problem. ArkSim is an open-source agent testing tool that simulates your end users automatically. It generates diverse interactions, follows up on ambiguous responses, and optimizes towards coverage and efficiency without requiring a single human tester.
Here's what it looks like in practice: one developer spent 6 months manually testing their financial AI agent, Agentic FinSearch. Within 30 minutes of using ArkSim, they had a full structured report that was ready to hand directly to their dev team. The report had conversation-level breakdowns, failure traces, and scoring reasoning.
ArkSim surfaced issues they'd missed for months:
- Prompt iteration bottleneck - ArkSim only needed user intent and domain context. It generated interactions and followed up on unclear responses automatically, eliminating multiple refinement rounds.
- Tool selection failures - The agent was inconsistently falling back on unstable web scraping instead of reliable data sources. ArkSim identified this within minutes; the fix was obvious once the trace was visible.
- Reporting that closed the loop - ArkSim's structured output made results immediately shareable, turning slow back-and-forth into a shared artifact both developers and PMs could work from directly.
The result wasn't just faster testing. It was seeing more.
The Bottom Line
If you're still testing your AI agent manually, you're not just losing time - you're structurally missing failures. The problem space is too large and dynamic for human review alone to catch.
ArkSim is open source. Test your agent the way real users behave.
If it helps, give us a ⭐ It means a lot to the team!