Your AI Agent Testing Workflow Is Broken. Here's What to Do Instead
A scenario you'll recognize
Wednesday, 9:40 PM.
A PM drops a message in Slack:
"This flow is still broken. I just reproduced the same issue by phrasing it slightly differently."
The engineer pulls up the logs. Thirty minutes later, they find it — an edge case. They tweak the prompt and redeploy.
The next morning, the PM tests again. Everything looks fine.
They're about to close the window, but try a few more variations.
Just by rephrasing the question, the agent breaks again.
"There's another issue…"
Fix, test, fix again. The loop runs for weeks. Eventually, everyone agrees it's probably good enough. So they ship.
Three days later, a real user hits a path no one has tested.
If you're building AI agents, this probably isn't a story. It's your last two weeks.
The real problem is that you can't tell when you're done.
The process has no finish line.
The engineer fixes the edge case. Redeploys. The PM retests. This time it works. A few hours later: "Found something else." Nobody is doing anything wrong. But the loop never ends.
Every fix is also a risk.
Prompt changes are rarely isolated. Adjusting one behavior can break another, somewhere nobody thinks to look. Manually retesting every affected path takes hours no one has. So the team spot-checks what seems related, skips the rest, and ships when the deadline arrives , not when they're confident nothing regressed.
You tested dozens of paths. Your users will find thousands.
Real users don't follow the paths your team wrote down. They rephrase, go off-topic, type things nobody anticipated. Manual testing covers a few dozen scenarios. Your users will find thousands.
The longer the project runs, the less you can trust what you've already tested.
A new tool gets added. The model gets swapped. Three prompts get rewritten over two sprints. Each change is small, but they compound. By the time the agent ships, the gap between what has been tested and what's actually running can be weeks wide.
"This doesn't feel right" is not a bug report.
The PM files a vague ticket. The engineer reads it three times, makes a change, and hopes it lands. No shared definition of "fixed." No metric for "ready." Just two people doing their best across a gap that language can't bridge.
What's actually broken
The problem isn't that teams aren't working hard enough.
The problem is that you're using manual, single-turn testing to validate a multi-turn, non-deterministic system.
AI agents operate across evolving contexts: users rephrase, clarify, go off-topic, behave unpredictably. But most testing still treats them like static scripts: one prompt in, one output checked.
This mismatch means you only test what you can anticipate. What breaks in production is everything you didn't.
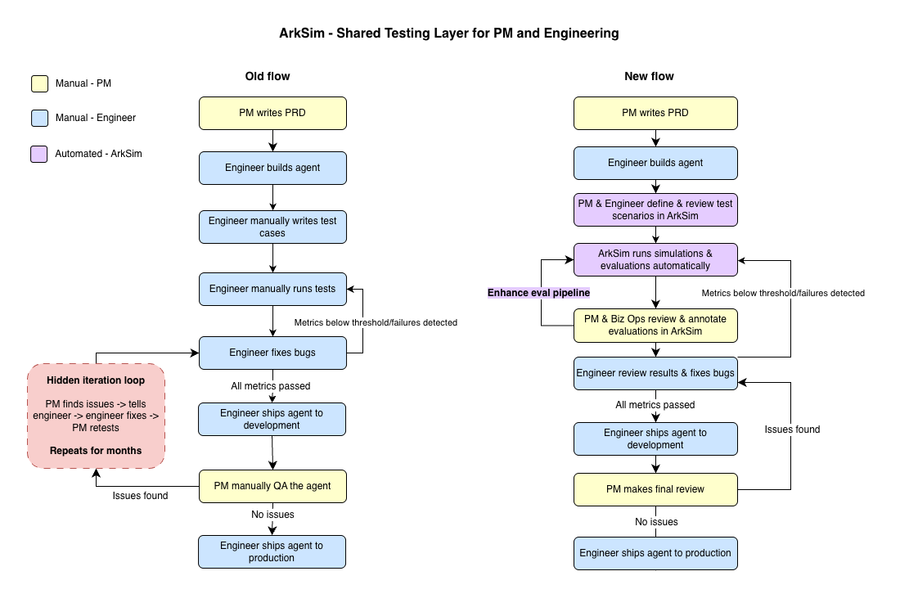
What the workflow looks like when testing is systematic
Same Wednesday. 9:40 PM.
The PM opens a shared dashboard, filters the latest simulation run by failure type, and drops a link in Slack: "Three flows failing. Here are the paths."
The engineer clicks through exact inputs, exact outputs, and exact failure points. By 10:15, the fix is in. Regression runs automatically.
The next morning: completion rate up, fallback rate down. A number, not a feeling.
How ArkSim makes this possible
Every new deployment triggers a full test run.
ArkSim doesn't wait for the PM to schedule a QA session. Every time the agent changes — a prompt tweak, a new tool, or a model swap — it automatically generates hundreds of simulated interactions and runs them end-to-end. Not just happy-path scenarios, but adversarial inputs, edge cases, and the kind of rephrasings that real users actually type. By the time the engineer pushes the fix, the results are already waiting.
Bug reports become coordinates, not feelings.
When something fails, ArkSim shows the exact conversation path where the agent broke turn by turn, exactly as it failed. The PM shares a link. The engineer sees the same thing. No interpretation gap, no back-and-forth. The failure has already been reproduced and documented, ready to fix.
"Are we ready?" finally has an answer.
Before shipping, the team defines what "good" looks like: a goal completion rate above a threshold, a fallback rate below one, a tool call success rate above a defined threshold. ArkSim runs against those metrics on every build. When the numbers hit, the conversation shifts from "Does this feel ready?" to "The metrics passed. Let's ship."
One is a judgment call. The other is a decision.
One thing worth sitting with
AI agents rarely fail because the model wasn't good enough.
They fail because there was a path no one tested, a phrasing no one tried, and a failure that was always there. The team just didn't have a systematic way to catch it before users did.
The question is whether you find it before your users do.
⭐ Try our open source and give us a star: https://github.com/arklexai/arksim